Visualising Streaming Data from Memgraph and Graphlytic
In my quest to find a streamlined(pun intended) solution for a streaming data platform that integrates with a Graph Database that has Data Analytics/Analysis, Visualisations in real-time with a low-code requirement out of the box, and is Cloud-Native(on-prem and cloud) was a bit of an adventure. I landed on a tool chain, that I have quite enjoyed working with, allowing me to focus on solving the core problem/challenge at hand, instead of fighting system/platform/data engineering config/implementation issues. The tool chain implementation and operational workflow looks like this:
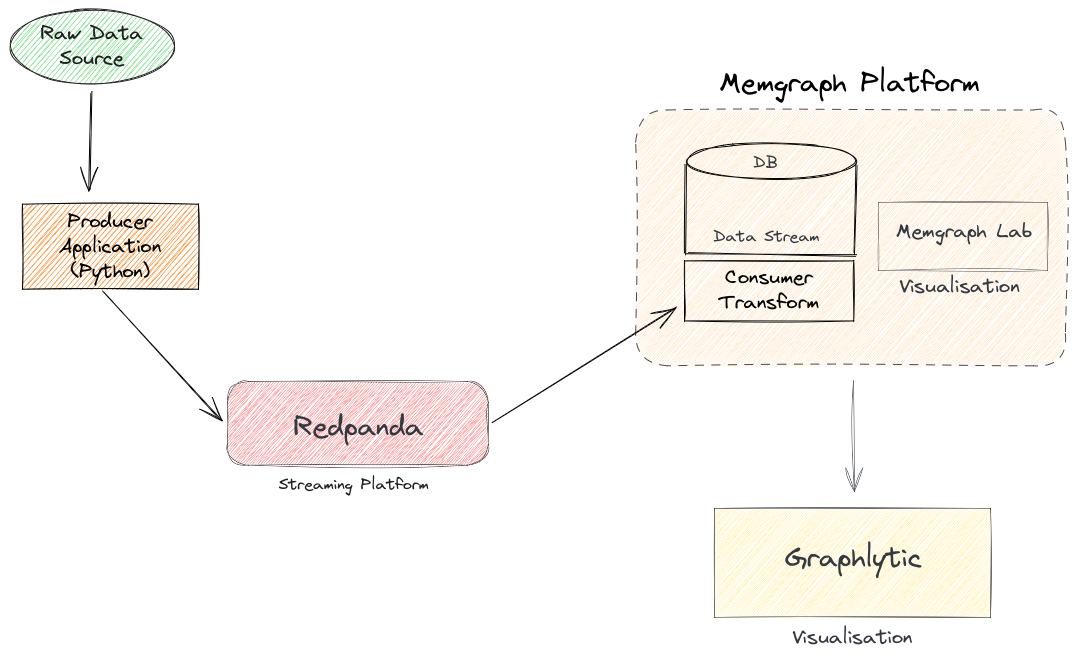
If you don’t like reading and just want to jump straight into the above deployment, I have shared the following Github repo which has a docker compose file to launch the stack, with a sample movielens dataset that Memgraph also use to help people learn the foundations of the Memgraph platform and streaming data ==> GraphDB Streaming Ingestion Example
Redpanda: Streaming Data Platform
Ingesting data from a streaming data source, in near real-time / real-time, is one of the most challenging ingestion methods to do well. I have always thought Kafka was powerful with many features, but like Kubernetes, it needs a team of data/platform engineers to maintain it in production. So when I googled “Kafka simple alternative” Yahoo answered: Redpanda which is a drop in replacement for Kafka without the complexity of Kafka.. I had to give it a go.
Deploying Redpanda to test and get a proof of concept of the ground was simple, as is with most cloud native tools today. With Docker Compose you can spin up the Redpanda Core streaming platform and a Redpanda Web Console very quickly. What impressed me here is how light the Redpanda deployment was, and how intuitive and useful the Web Console was to monitor/admin the streaming topics, schema registry, consumer groups etc… very helpful!
When writing the Producer app for Redpanda, you effectively use the same apache-kafka python library and just point the endpoint to the Redpanda cluster, instead of Kafka. If you followed the example in the Graph Streams Github Repo shared above, Here is a code snippet from there of the python(v3.8+) producer for the movielens dataset. To emulate a streaming data source, the producer application loops through a csv dataset.
from kafka import KafkaProducer
import csv
import json
import time
DATA_RATINGS = "./datasets/movielens/ratings.csv"
DATA_MOVIES = "./datasets/movielens/movies.csv"
stream_delay = 1
topic = "ratings"
movies_dict = {}
producer = KafkaProducer(
bootstrap_servers = "localhost:19092"
)
def on_success(metadata):
print(f"Message produced to topic '{metadata.topic}' at offset {metadata.offset}")
def on_error(e):
print(f"Error sending message: {e}")
# Generate data from raw csv dataset
def generate():
while True:
with open(DATA_RATINGS) as file:
csvReader = csv.DictReader(file)
for rows in csvReader:
data = {
'userId': rows['userId'],
'movie': movies_dict[rows['movieId']],
'rating': rows['rating'],
'timestamp': rows['timestamp'],
}
yield data
# Kafka/Redpanda Producer
def main():
with open(DATA_MOVIES) as file:
csvReader = csv.DictReader(file)
for rows in csvReader:
movieId = rows['movieId']
movies_dict[movieId] = {
'movieId': movieId,
'title': rows['title'],
'genres': rows['genres'].split('|')
}
message = generate()
while True:
try:
mssg = json.dumps(next(message)).encode('utf8')
future = producer.send(topic, mssg)
print(mssg)
future.add_callback(on_success)
future.add_errback(on_error)
producer.flush()
time.sleep(stream_delay)
except Exception as e:
print(f"Error: {e}")
if __name__ == "__main__":
main()Memgraph: Graph Database, Visualisation, Analysis, Algorithms
I found Memgraph a refreshing change from Neo4j. Memgraph does what it says on the tin, 8x faster than Neo4j and higher throughput. You could argue this wildly depends on the data architect who designed the data platform, but I found Memgraph is not as bloated as Neo4j and still uses Cypher as its query language and is Bolt compatible. I also found the implementation of Memgraph less complex. Memgraph can also be a drop-in replacement for Neo4j.
Using the Graph-Streams example Repo, you can start the complete Memgraph platform as follows;
docker compose up memgraph-platormThe beauty about launching Memgraph-Platform is that you get all the Graph candy in one box;
- The Core Graph Database
- MAGE : Memgraph Advanced Graph Extensions, which are open-source algorithm analytic modules to help accelerate extract valuable data insights
- Memgraph Labs: is the Web Console UI/Visualisation tool, which just works
- Streams: Has the streaming consumer module built-in which performs the transform of streaming data and persists it into the Memgraph Graph DB.
- And more …
Memgraph Streams
One of the biggest enablers Memgraph does for you, is how it simplifies the ingestion and visualisation of data from a streaming source in real-time/near real-time. Memgraph Streams provides transformation module API’s in C and Python. Here is a snippet of the python transformation module we need for the movielens dataset example;
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"MERGE (u)-[r:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
parameters={
"userId": movie_dict["userId"],
"movieId": movie_dict["movie"]["movieId"],
"title": movie_dict["movie"]["title"],
"genres": movie_dict["movie"]["genres"],
"rating": movie_dict["rating"],
"timestamp": movie_dict["timestamp"]}))
return result_queriesCreating the Stream Consumer in Memgraph
To create and start the Redpanda/Kafka consumer of the movielens Topic, you must first upload your transform module as per Graph-Streams github repo instructions and then you use the Cypher query statement to create the stream consumer like the following; (You can also enter this query in the Memgraph Lab => Query Execution section.)
CREATE KAFKA STREAM movie_ratings
TOPICS ratings
TRANSFORM movielens.rating
BOOTSTRAP_SERVERS 'redpanda:9092';The Bootstrap server in this case is using the docker compose service name of redpanda and the port it is advertised on. Because Memgraph is also running in the same docker network, you can just use the service name as the host_address for BOOTSTRAP_SERVERS.
And now you are ready to visualise your streaming dataset in Memgraph Lab. I have included a few simple queries in the Graph-Streams repo under memgraph/data-streams/movielens-query.cql
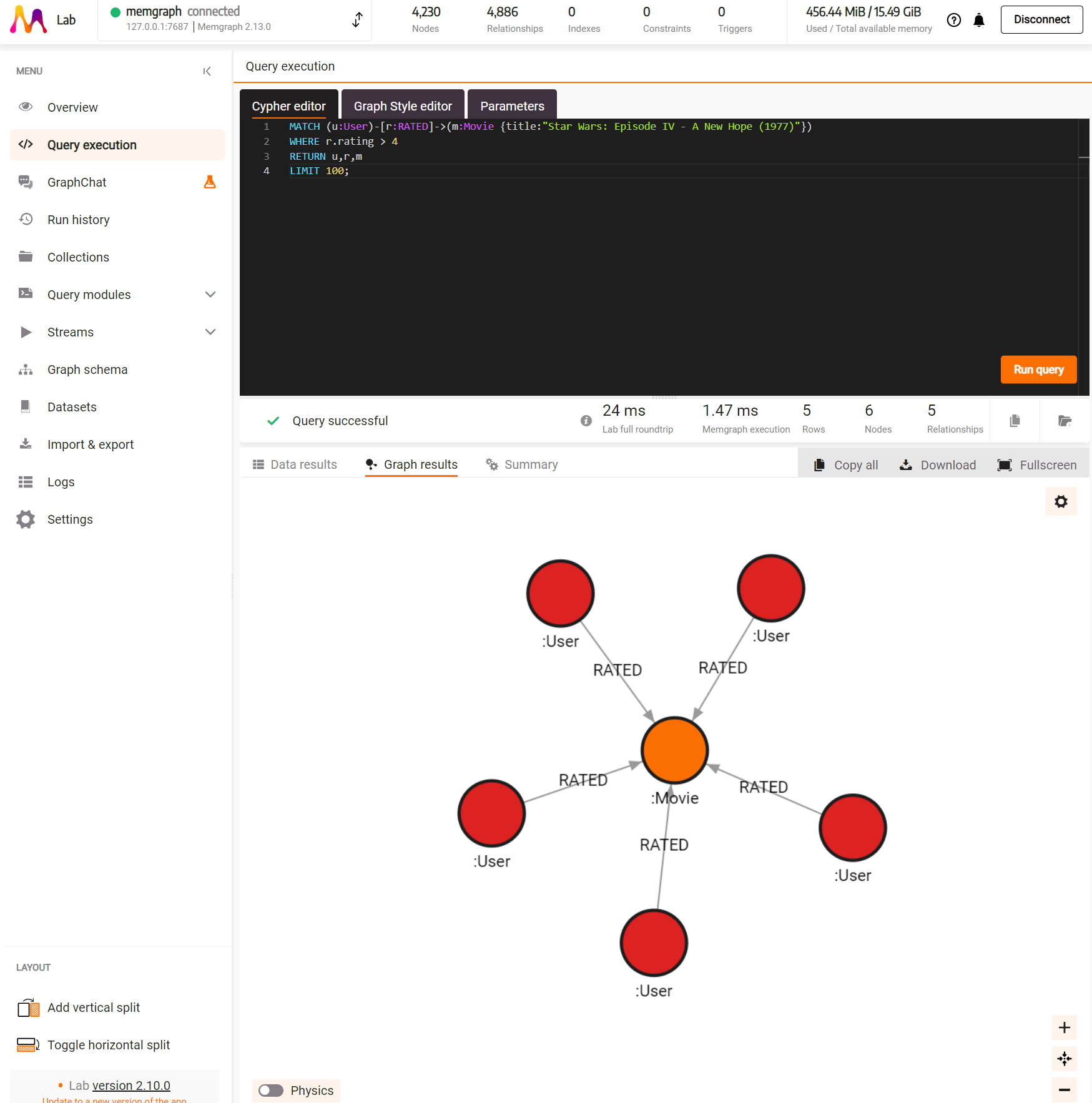
Albeit this is a very simple example, you are now in a great poistion to implement your own data models/datasets.
Next Level Graph Visualisation: Graphlytic
If you want to take the visualisation of Graph databases to the next level Graphlytic offer a feature rich Graph visualisation and analytics platform with Cloud Native deployment options or Managed Cloud. The Edition I used to experiment with was the Free On-Premise Lite-Edition (Single User). I have also included Graphlytic as a docker compose service to launch. You may have to grab your own Single-User license key to activate the install, which is generated over an email. You don’t need to speak to any sales people/bots.
docker compose up graphlyticAfter it launches, just enter in the local url localhost:8090 to start using Graphytic.
To connect Graphlytic to Memgraph, you can just use the Bolt protocol, as the latest versions of Memgraph now natively support Bolt, here is a connection example which worked for me with the config in the Graph-Streams github repo;
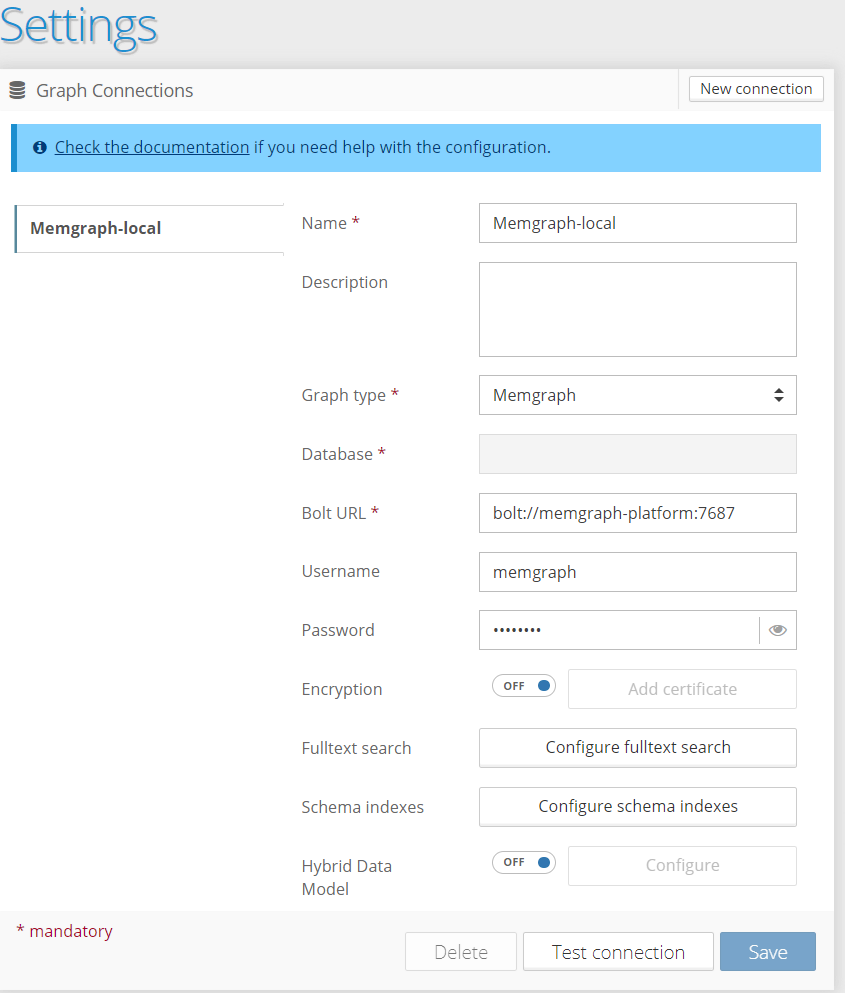
I’m still exploring Graphlytics numerous features and it’s potential, and so far it has been impressive. I will definitely write up an article just on Graphlytic soon and share my wins/losses.
Graphing out
Whilst I did not do a technical deep dive into the whole stack, each component(Redpanda, Memgraph, Memgraph Labs, Memgraph Mage, Graphlytic) all need their own blog on how to best deploy them in production with data engineering best practices. The examples used in this article are for sandbox/experiment environments. I will tweak the production deployment of this stack with the Hashicorp stack.